 High-level description of the XFlow architecture.
High-level description of the XFlow architecture.Abstract
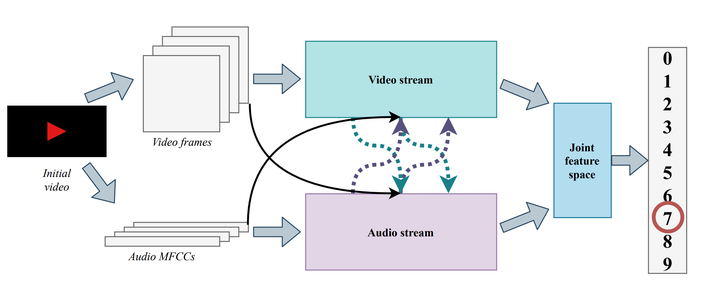
In recent years, there have been numerous developments towards solving multimodal tasks, aiming to learn a stronger representation than through a single modality. Certain aspects of the data can be particularly useful in this case - for example, correlations in the space or time domain across modalities - but should be wisely exploited in order to benefit from their full predictive potential. We propose two deep learning architectures with multimodal cross-connections that allow for dataflow between several feature extractors (XFlow). Our models derive more interpretable features and achieve better performances than models which do not exchange representations, usefully exploiting correlations between audio and visual data, which have a different dimensionality and are nontrivially exchangeable. Our work improves on existing multimodal deep learning algorithms in two essential ways: (1) it presents a novel method for performing cross-modality (before features are learned from individual modalities) and (2) extends the previously proposed cross-connections which only transfer information between streams that process compatible data. Illustrating some of the representations learned by the connections, we analyse their contribution to the increase in discrimination ability and reveal their compatibility with a lip-reading network intermediate representation. We provide the research community with Digits, a new dataset consisting of three data types extracted from videos of people saying the digits 0-9. Results show that both cross-modal architectures outperform their baselines (by up to 11.5%) when evaluated on the AVletters, CUAVE and Digits datasets, achieving state-of-the-art results. A shorter version was also presented at the Workshop on Computational Models for Crossmodal Learning (CMCML) at The 7th Joint IEEE International Conference on Development and Learning and on Epigenetic Robotics (IEEE ICDL-EPIROB 2017) and at the ARM Research Summit 2017.
Dr Cătălina Cangea
Staff Research Scientist
Staff Research Scientist with a decade of ML experience, Lyria post-training and evals lead, with a PhD from the University of Cambridge, and inhaler of music :)